A while back, I noticed that whenever I typed https:// into the search bar in Firefox on my phone, Google would helpfully try and autocomplete my search with a number of random domains. This immediatly nerd sniped me, so I thought it might be interesting to see what we can find amongst these recommendations.
How Google Gets Recommendations
Firstly, a quick dive into how we can automate fetching these URLs.
I was able to replicate this behaviour in Chrome on my Laptop so I fired up mitmproxy and set to work throwing queries into the searchbar to work out how I could automate the procedure of fetching domains. Rather disappointingly, just as I was getting into Hackerman mode, I found this is actually really simple
2021-11-05 21:36:39 GET https://www.google.com/complete/search?client=firefox&q=mitm HTTP/2.
It was also at that point, I realised I could also just fetch the requests from the DevTools:

But that’s worth less nerd cred. And anyway, having two ways of doing something proves the point (or at least that’s what I’ll tell myself…)
One thing I wanted to mention, because it’s kind of interesting - the xssi parameter appears to be a boolean that controls whether the response is JSON or JSONP - with xssi=f, it generates the following response:
window.google.ac.h([[["h\u003cb\u003eotmail\u003c\/b\u003e",0,[512,433,131]],["harvey norman",46,[512,433,199,291],{"zh":"Harvey Norman","zi":"","zp":{"gs_ssp":"eJzj4tTP1TewKM-ON1VgNGB0YPDizUgsKkutVMjLL8pNzAMAex8I4A"},"zs":"https://encrypted-tbn0.gstatic.com/images?q\u003dtbn:ANd9GcSlzOUDNfFz9IlkY-qQ7l1D_wy0XvILECjUEMvf3eR6\u0026s\u003d10"}],["hoyts",46,[512,433,131,199,291],{"zh":"Hoyts","zi":"","zp":{"gs_ssp":"eJzj4tTP1TcwMUszLVdgNGB0YPBizcivLCkGADv9BaM"},"zs":"https://encrypted-tbn0.gstatic.com/images?q\u003dtbn:ANd9GcT9sHCAXmodSXF5a_Qp_5jdjN7gFT1DP7dLIirWY230\u0026s\u003d10"}],["hungry jacks",46,[512,433,131,199,291],{"zh":"Hungry Jack\u0026#39;s","zi":"","zp":{"gs_ssp":"eJzj4tLP1TcwTqowKCtUYDRgdGDw4skozUsvqlTISkzOLgYAfoMI5Q"},"zs":"https://encrypted-tbn0.gstatic.com/images?q\u003dtbn:ANd9GcRJ-YAeX1E4hpUzAQxZPPtirsril51jomsTrjWEP4cx7w\u0026s\u003d10"}],["h\u003cb\u003eerald sun\u003c\/b\u003e",0,[433,131]],["h\u003cb\u003ei\u003c\/b\u003e",0,[512]],["h\u003cb\u003eotdoc\u003c\/b\u003e",0,[512,433]],["harry potter",46,[512],{"zh":"Albus Severus Potter","zi":"Harry Potter character","zp":{"gs_ssp":"eJzj4tTP1Tcwt0hLKzdg9OLJSCwqqlQoyC8pSS0CAF_WCCw"},"zs":"https://encrypted-tbn0.gstatic.com/images?q\u003dtbn:ANd9GcSCrvZ3tGPIFRfW3Zzsk1QeceDUhGkgzEQrWSEJ9K0H\u0026s\u003d10"}],["henry ruggs",46,[433,131],{"zh":"Henry Ruggs III","zi":"American football wide receiver","zp":{"gs_ssp":"eJzj4tVP1zc0zDA3MyizrIo3YPTizkjNK6pUKCpNTy8GAHOICMA"},"zs":"https://encrypted-tbn0.gstatic.com/images?q\u003dtbn:ANd9GcTfEVOblWzSPm3nXLUWo2CMl4ESmS5pAVWZa9V7QOY-\u0026s\u003d10"}],["h\u0026amp;m",46,[512,433,199,291],{"zh":"H\u0026amp;M","zi":"","zp":{"gs_ssp":"eJzj4tTP1TcwTLEoKFJgNGB0YPBizlDLBQAzRQSY"},"zs":"https://encrypted-tbn0.gstatic.com/images?q\u003dtbn:ANd9GcSIfN_4sMl-G1VjI1e9tIQGUqsw_tYYqJB0iJEpnGMS\u0026s\u003d10"}]],{"q":"uj2cGaAL_xnrnujhmKxcnSxjTrw"}])
(Note the JSON being put in a call to window.google.ac.h - this is indicative that this is meant to be loaded in a <script> tag)
With xssi=t, we get something… sort of JSONy?
)]}'
[[["https\u003cb\u003e //aka.ms/remoteconnect\u003c\/b\u003e",0,[512,433]],["\u003cb\u003ehttps://aka.ms/remoteconnect\u003c\/b\u003e",0,[512]],["https\u003cb\u003e //auth.streamotion.com au/activate\u003c\/b\u003e",0,[512]],["https\u003cb\u003e //www.microsoft.com/link\u003c\/b\u003e",0,[512,433,131]],["https\u003cb\u003e //www.twitch.tv/activate\u003c\/b\u003e",0,[512,433]],["https\u003cb\u003e //ij.start.cannon\u003c\/b\u003e",0,[512,433]],["https\u003cb\u003e //plex.tv/link\u003c\/b\u003e",0,[512,433,131]],["\u003cb\u003ehttps://nswhvam.health.nsw.gov.au/vam\u003c\/b\u003e",0,[512]],["https\u003cb\u003e //spotify.com/pair\u003c\/b\u003e",0,[512,433]],["https\u003cb\u003e //i.clonephone.coloros.com/download\u003c\/b\u003e",0,[512,433,131]]],{"q":"8KSX5HzGQRiy5kuzNtK_ue4zSEI"}]
Note the first line there - that’s weird. It feels like this is tacked onto the end of another script and then evald, with that first line closing some statement that preceeds this one, but that’s just speculation. You’ll also note the \u003cb\u003e there - that’s an encoded <b> tag! This is definitely dumped into the DOM somewhere - very interesting indeed.
At any rate, that weird output only appears with the client=gws-wiz flag. If we instead pretend that we are Firefox, we get more normal JSON, that we can parse with jq:
curl -s 'https://www.google.com/complete/search?client=firefox&q=https' | jq -r '.[1] | del(.[0]) | .[]'
https /auth.streamotion.com.au/activate
https //auth.streamotion.com au/activate
https //ij.start.cannon
https //www.google classroom
https //kahoot.it login
https //check1 student.cese.nsw.gov.au
https //192.168.l.l
https //kahoot..com
https //www.mygovid.gov.au login
Getting some Recommendations
All of these appear to be mispellings or other things that make Google not recognised as a URL. From there it ends up in the index, and then gets served up as a recommendation to people like me. If we prompt the search with another letter, e.g. ‘a’ then we get websites starting with that letter (or combination of letters). Considering that, I fired up some bash to run through all the combinations of two letters and pull the autocompletes:
for x in {a..z}; do for y in {a..z}; do curl -s 'https://www.google.com/complete/search?client=firefox&q=https://'$x$y | jq -r '.[1] | del(.[0]) | .[]'; sleep 0.5; done; done | tee weird_urls
You can see this script, and the resulting files in the Github Repo. Some interesting first glance observations from just quickly scrolling through the output:
- Some results didn’t contain
https://at all. Most of these were URLs likeabr.gov.au, but some were clearly just searches likeaegis synergen pay. Why Google suggests those as autocompletes I don’t know - The search results were still rather obviously attached to my location (Sydney, Australia) with many results from Australia, New Zealand, India, and Malaysia. I imagine this is Geolocated through my IP address
- There was a weirdly large amount of .gov and .mil addresses if Google was using my IP address to locate me. Do I live near a secret US military base?
- A lot of results… look like URLs but aren’t. Many have
https //(’ ’ rather than ‘:’), which is strange to me - are so many people missing the colon key when typing out a URL? - Theres a few domains that I’m a bit scared to open. Mostly .ir and clearly internal domains
- There’s a Rick Roll in there (
dqw4w9wgxcq)
It was clear that I was going to have to normalize these results before I could do any actual analysis on them. To that end, I ended up throwing together a quick (read: hacky) Python script to filter out obviously non URLs, and try and fix the ones that actually did look like something. That trimmed about 300 non URLs out of the list, giving us ~5500 to play with.
Some Analysis
5500 URLs is a bit much to go through by hand, so let’s do some analysis on these to get some stats before we delve in.
Top Hostnames
Perhaps unsurprisingly, the vast majority of hostnames only appeared once. The top 30 or so occured 5 or more times, and I thought those were worth a delve into. In each request, I was receiving back 5 autocompletes so appearing 5 times means a domain took up all those slots.
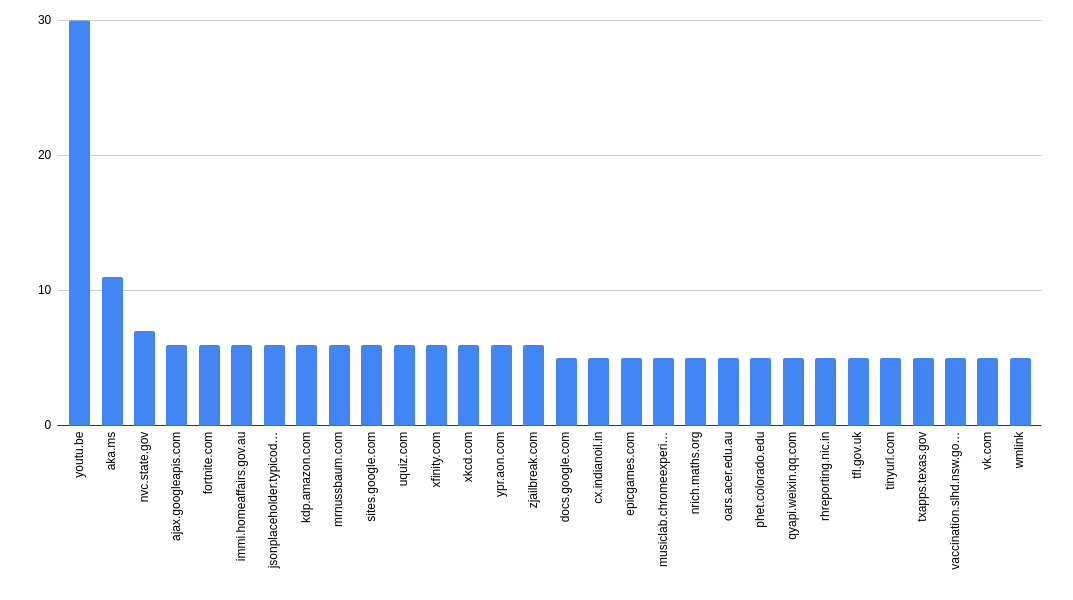
The first, by a big margin there is youtu.be - YouTubes URL shortener, but we’ll get to that in a minute. You can see from the graph that we’ve stumbled onto some interesting domains already:
aka.ms- Microsort Shortlinksqyapi.weixin.qq.com- The API for WeChatvk.com- A Russian Social Network that I didn’t know aboutwmlink- This isn’t actually a domain (it doesn’t have a TLD) but appears in 5 results. Maybe an internal WallMart URL? (i.e. Do they run split brain DNS and make this an actual domain inside their network?)
Top Paths
Similar to hostnames, we can look at the top paths. Ignoring the root path (either blank or ‘/’) we get the following:
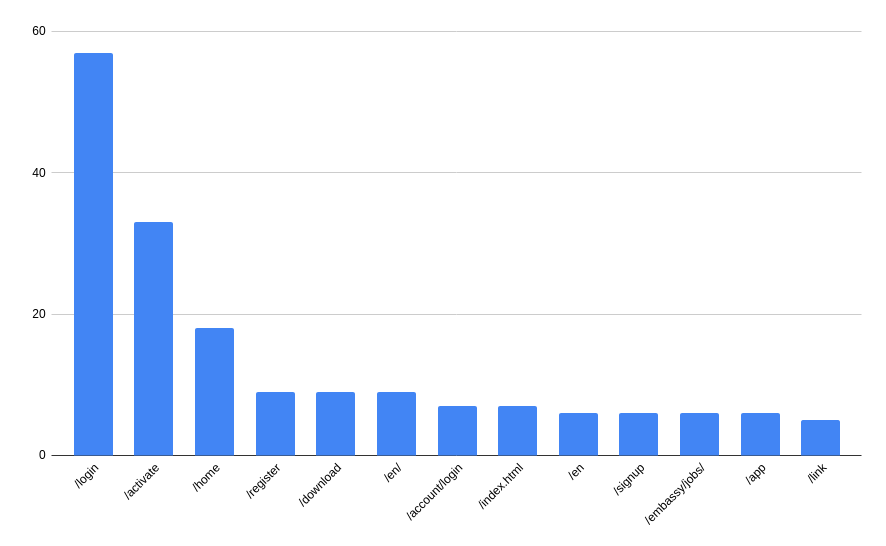
That’s a lot of log in screens! But that’s perhaps unsurprising - I can imagine that a lot of people are typing login URLs directly.
How many of these actually go anywhere?
It’s probably worthwhile working out how many of these URLs actually go anymore. I’d imagine that most of these will probably not go resolve, so I tried to do an HTTP request to each URL on the list, marking those that returned an HTTP status code < 400 (i.e. redirects, and 200 status’). That cuts the list in two with 3039 of the URLs not working, and 2495 of them actually returning a response. That’s likely to include some transient server failures, but hey. Of these, we can run those same graphs:
For hosts:
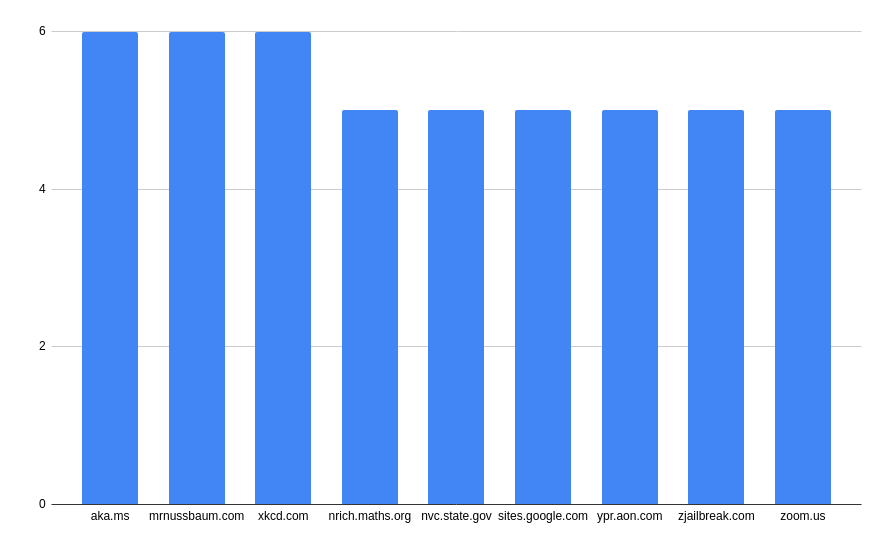
And for paths:
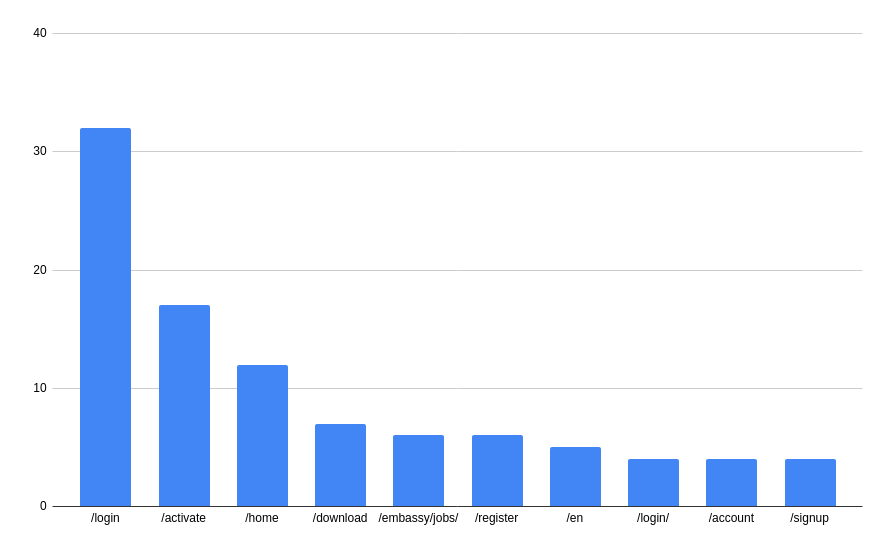
That gives us something to work with!
Manual Analysis
Now that we have an idea of the breakdowns of hosts and paths, we can do some manual investigation on what some of these top domains/paths actually are. To that end, I popped open a Fedora VM and went to clicking.
youtu.be
Even though we filtered for 200 status’, none of these worked. This is because YouTube is serving a 200, and then rejecting the video ID inside the playback window. If I had to guess, these are probably copyright infringing videos.
aka.ms
The majority of these paths were for aka.ms/remoteconnect - it appears that this is used to connect devices to your Microsoft account. My Niece insists that she used this link to play Minecraft on her X-Box, but I can’t verify that.
mrnussbaum.com
This appears to be a Kids game website. Lot’s of educational games etc. I guess it would make sense that kids or teachers might mistype a URL, or share that mispelling out to all their students for it to end up mispelled in the index
xkcd.com
No explanation needed here, xkcd is a webcomic. Although the results might be interesting as to which ones people were searching for. In order of the autocomplete recommendations:
- https://xkcd.com/1732/
- https://xkcd.com/2496/
- https://xkcd.com/927/
- https://xkcd.com/2501/
- https://xkcd.com/2509/
sites.google.com
All of these were for sites.google.com/education.nsw.gov.au, which I thought was interesting. Either education.nsw.gov.au is actually a Google Site with a custom domain (or used to be?), or this is a very convincing phishing site.
zoom.us
Most of these were rather innocuous - links to public pages on the Zoom website and the like. A few of these were virtual classrooms and company meetings that I got bumped into the waiting for though, which was kind of scary. I’ve removed those links from the published output and emailed the relevant people (or at least, those that I could find contact information for) to get them to add meeting passcode - fingers crossed I don’t get CFAA’d the next time I go through SFO.
/login screens
Yet again, most of these were school related - login screens for .edu and equivalent sites, There was definitely some interesting ones there though - a onelogin for Uber, a Workday for WalMart, logins for the Nepalese Stock Exchange, and more. This is definitely a good resource if you wanted to start phishing one of these companies - you can pretty easily work out what services they’re using.
/download s
Most of these were boring - normal apps that people download - Ubuntu, Zoom, AnyDesk, OBS etc. We did find a few internal applications though, mostly on beekeeper.io which bills itself as “The Essential Platform for Frontline Workers”, so I’ve removed those links from the listing as well and contacted the relevant companies just in case.
Wrapping this up
This was certainly an interesting nerd-snipe. We found a bunch of URLs, most of which were innocuous, but a few we were definitely not supposed to find. I think that this really lends evidence to the idea that if it’s on the web, you can’t expect privacy from it. I’ll update here if I get anything interesting back from the companies I’ve contacted, but in the mean time I’ve uploaded the code and autocompletes gathered (without the sensitive domains I spotted) to my github. Have a roam around! See whether you can find anything interesting. Feel free to use fetch-some-autocompletes.sh to get your own list of URLs and run some analysis - I’d be interesting in what you can find!